
FAQ robots.txt: часто задаваемые вопросы

- Robots.txt - что это?
- Нужен или нет robots.txt?
- Где находится файл robots.txt?
- Как выглядит стандартный robots.txt?
- Что должно быть в robots.txt?
- Как выглядит Robots.txt для Гугла и Яндекса?
- Как указать главное зеркало в robots.txt?
- Как прописать карту сайта в robots.txt?
- Что обозначают символы в robots.txt?
- Как настроить robots.txt?
- Как проверить robots.txt?
- Ошибки в robots.txt
Robots.txt - что это?
Файл robots.txt — это индексный файл в текстовом формате, который рекомендует поисковым роботам (например, Google, Yandex) какие страницы сканировать, а какие нет.
Нужен или нет robots.txt?
Однозначно да. Он помогает поисковым роботам быстрее разобраться какие страницы нужно индексировать, а какие нет.
Где находится файл robots.txt?
Файл располагается в корневой папке сайта и доступный для просмотра по адресу: https://site.ua/robots.txt
Как выглядит стандартный robots.txt?
Robots.txt пример:
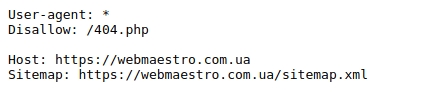
Что должно быть в robots.txt?
Атрибуты robots.txt:
- User-agent — описывает каким именно роботам нужно смотреть инструкцию. Существует около 300 поисковых роботов (Googlebot, Yandexbot и т.д.). Чтобы указать инструкции сразу для всех роботов следует прописать:
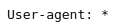
Другие роботы:- Ahrefsbot;
- Exabot;
- SemrushBot;
- Baiduspider;
- Mail.RU_Bot.
- Disallow — указывает роботу, что не нужно сканировать.
Открыть для сканирования весь сайт (robots.txt разрешить все):.png)
Запретить сканирование всего сайта (robots.txt запретить все):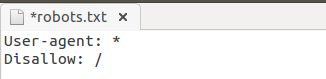
Robots.txt запретить индексацию папки: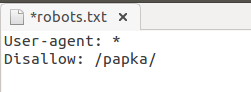
Запретить индексацию страницы в robots.txt: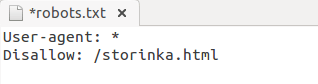
Запретить индексацию конкретного файла: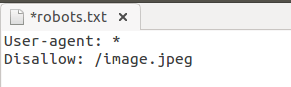
Запрет индексации всех файлов на сайте с расширением .pdf: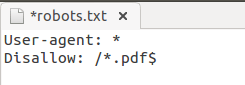
Запретить индексацию поддомена в robots.txt:
Каждый поддомен имеет свой файл robots.txt. Если его нет — создайте и добавьте в корневую папку поддомена.
Закрыть все кроме главной в robots.txt: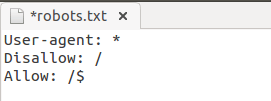
- Allow — разрешает роботу сканировать сайт/папку/конкретную страницу.
Например, чтобы разрешить роботу сканировать страницы каталога, а все остальное закрыть: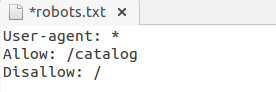
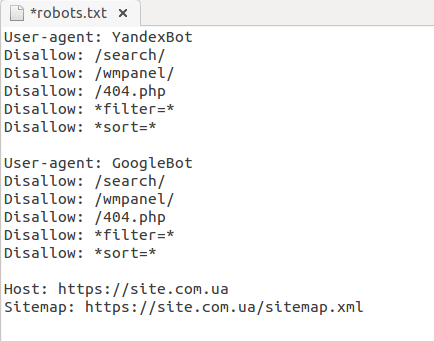
Как выглядит Robots.txt для Гугла и Яндекса?
Как указать главное зеркало в robots.txt?
Для обозначения главного зеркала (копии сайта, доступной по разным адресам) используют атрибут Host.
Host в robots.txt: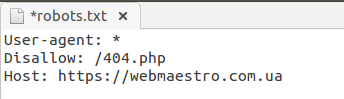
Как прописать карту сайта в robots.txt?
Карта сайта (sitemap.xml) сообщает поисковым роботам приоритетные страницы для индексации. Она находится по адресу: https://site.com/sitemap.xml.
Sitemap в robots.txt:.png)
Что обозначают символы в robots.txt?
Наиболее часто используются следующие символы:
- “/” - закрытие от робота весь сайт/папку/страницу;
- “*” - любая последовательность символов;
- “$” - ограничение действия знака “*”;
- “#” - комментарии, которые не учитываются роботами.
Как настроить robots.txt?
В файле обязательно нужно отдельно для каждого робота прописать, что открыто для сканирования и что закрыто, прописать хост и карту сайта.
Файлы robots.txt различаются между собой в зависимости от используемой CMS.
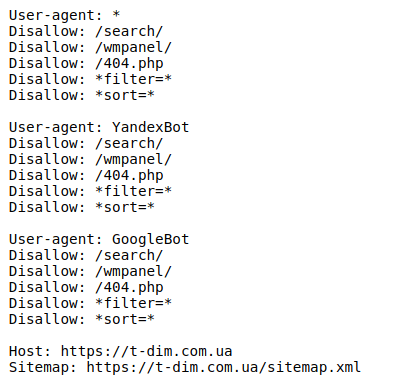
Рекомендуем закрывать от индексации страницы: авторизации, фильтрации, поиска, страницу 404, вход в админку.
Пример идеального robots.txt:
Как проверить robots.txt?
Чтобы проверить валидность robots.txt (правильно ли заполнен файл) — используйте инструмент для вебмастеров Google Search Console. Для этого достаточно ввести код файла в форму, указать сайт и Вы получите отчет о корректности файла: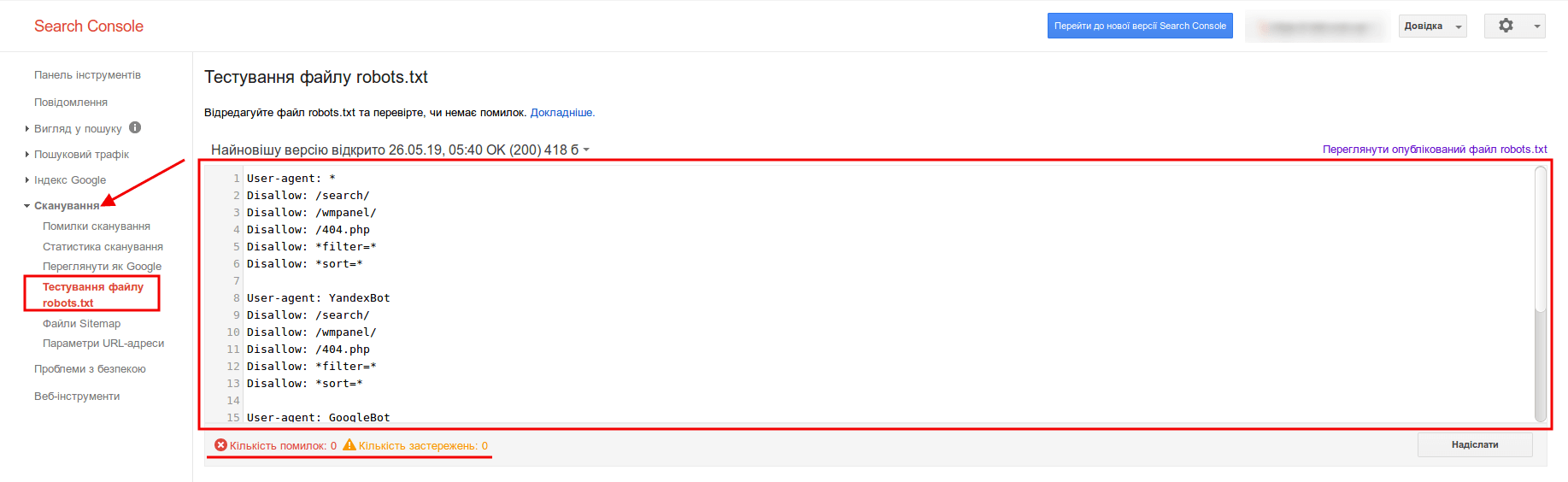
Ошибки в robots.txt
- Перепутали местами инструкции.
Неправильно: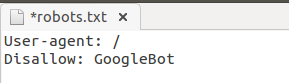
Правильно: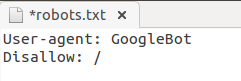
- Записали пару директорий сразу в одной инструкции:
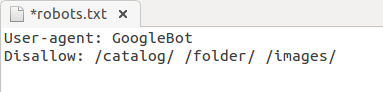
- Не правильное название файла — не Robot.txt и не ROBOTS.TXT, а robots.txt!
- Правило User-agent не должно быть пустым, обязательно нужно указывать для каких роботов оно действует.
- Следите, чтобы не указать лишних символов в файле (“/”, “*”, “$” и т.д.).
- Не открывайте для сканирования страницы, которые не нужны в индексе.
Подойдите со всей ответственностью к формированию файла robots.txt — и будет Вам счастье ;)
![SEO БОМБА от WEBMAESTRO [Мультиканальная раскрутка], блог, фото](/img/blog/20180324192737_.jpg)


